相信大傢都有類似的體驗,現在各種桌面在線詞典在盈利的壓力下,廣告越來越多,查個單詞都要提示你註冊用戶,加入社區,添加好友,關註新聞,學習每日一句,推薦英語課程,搞得啟動越來越慢,幹擾太多瞭,稍不留神點錯瞭就萬劫不復瞭。
我就想要簡單直接的查詞即可,可惜商業免費詞典都不滿足我的需求,後來把《XX詞霸》,《X道詞典》都卸載瞭,轉投免費開源的 GoldenDict(可以安裝各種離線詞典),掛載《21世紀》搭配《朗文》《劍橋高階》等學習詞典,確實很好用,可惜這些大部頭詞典的收詞量太少瞭,查10個詞,有3個查不出來,又得點開網頁,有道搜不到去金山,金山查不出來去必應,必應再查不出來就要點開谷歌翻譯和 wiktionary 和 Urban Dictionary 等,有時候網絡不好,點不開,有時候 vps 抽風谷歌翻譯用不瞭。
這年頭難道就沒有辦法讓你隨心所欲簡單快捷的查個單詞?於是我找到一個解決方案:現在網上公開免費資源那麼多,既然找不到現成的,自己做一個收詞量超大的詞典放到 GoldenDict / 手機歐陸 裡不就完瞭?
然後我制作瞭 340萬收詞量的開源詞典《簡明英漢增強版》(支持 GoldenDict, 歐陸詞典,BlueDict,mdict,edwin,Kindle 等),受到很多網友們的歡迎,半年不到,積累瞭五萬多的下載量。其後再接再厲,補充更多短語、諺語、新詞、俚語和專業術語,並對前20萬基礎詞匯使用必應釋義進行瞭校對,最終發佈這個收錄 432萬詞條的《簡明英漢必應版》。
網上有的它有,網上沒有的它也有!!收詞量 432萬是什麼概念,參考下面:
- OALD8:7.2萬詞條
- 朗文5:6.2萬詞條
- Merriam-Webster's Collegiate Dictionary:11.9萬
- 柯林斯 Cobuild 5:3.4萬
- 21世紀:37.7萬
- 有道本地增強版離線詞庫:40萬
- 歐陸離線詞庫:40萬
整合瞭市面上各類免費和開源資料,利用 BNC/COCA 語料庫進行詞頻矯正,並使用 NodeBox, WordNet 等自然語言處理工具包對各類時態語態,派生詞等進行補充和標註。再根據考試大綱和柯林斯星級還有牛津 3000核心詞進行標註,讓你一眼就能看出這個單詞的重要性。
演示1:基本使用
看上面 GoldenDict放在最上面的《簡明英漢必應版》,請忽略下面的劍橋高階,上面單詞,下面音標和解釋,這些沒有區別,關鍵標註有四處:
- 音標後面:K 代表是牛津3000核心詞匯,2代表是柯林斯兩星詞。
- 下面的衍生詞:各類簡明英漢詞典都沒有,我用 NodeBox + BNC 語料庫分析生成的。
- 考試大綱詞匯標註,是否是四級詞匯?考研詞匯?
- 大綱後面的詞頻標註:8139/8803 前面代表 COCA 詞頻(按COCA詞頻高低排序,第8139個單詞),後面是 BNC詞頻。
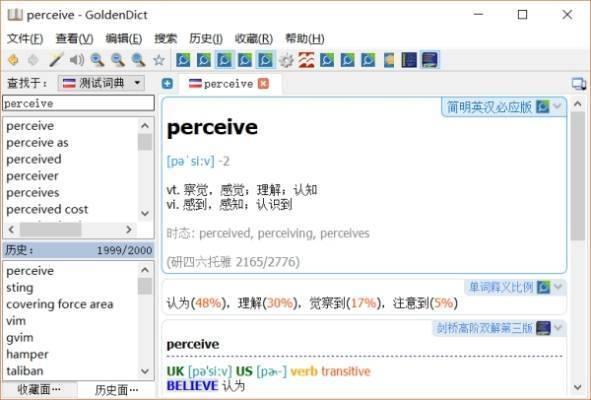
再來一張,perceive 不再牛津3000裡,所以音標後沒有K,但是還有2,因為他是柯林斯二星詞匯。
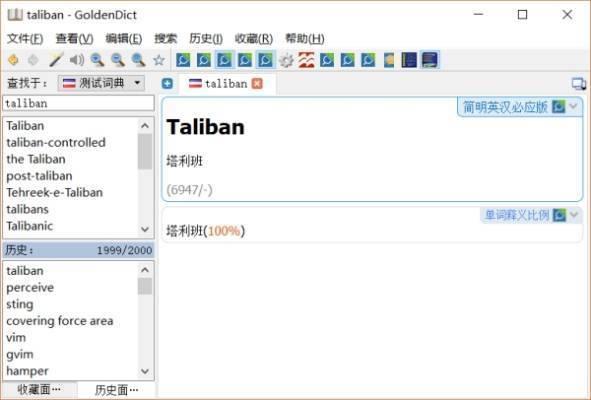
同時根據 COCA, BNC 的詞頻前20萬單詞進行校對補漏,兼顧現代和傳統,比如 Taliban (塔利班)這個詞,這個詞在各類 “簡明英漢詞典” 裡和其他大辭典裡都很難找到。BNC 前二十萬詞裡沒它,但是COCA(美國當代預料庫)裡排名 6947,簡直是重點高頻詞匯。 可能大傢都知道 牛津3000,BNC 和 COCA,避免有人不知道,還是科普下:
Oxford 3000
BNC:
COCA:
有瞭 COCA詞頻就好,為什麼還要提供 BNC詞頻呢?
很簡單,BNC詞頻統計的是近百年的各類資料,而當代語料庫隻統計瞭最近20年的。quay(碼頭)這個詞在當代語料庫裡排兩萬以外,你可能覺得是個沒必要掌握的冷詞,而BNC裡面卻排在第 8907名,基本算是一個高頻詞,為啥呢?可以想象過去乘船還是一個重要的交通工具,所以以往的各類文字資料對這個詞提的比較多。所以你要看懂百年以前的各類名著,國外的什麼帝王將相才子佳人,你會發現BNC的詞頻很管用;而新聞時政,COCA很管用。所以隻看一個,未免有失偏頗,兩者都提供,有個對比。
同時制作瞭一個“免音標版” 刪除瞭頭部的詞頭及音標(柯林斯和牛津三千信息整合到最後一行),也許你 GoldenDict / 手機歐陸 裡面已經有很多字典瞭,也許你不會象我一樣把它在 GoldenDict 裡面放第一個,那麼你可以用這個“去音標版”,來避免詞頭音標占用太大空間,和其他詞典一起放手機裡看著舒服,保持小巧緊湊,其他都一樣。
演示2:選詞
最早的《簡明英漢詞典》和《朗道詞典》,都號稱收詞 40萬左右,但裡面光各種醫學化學專用名詞就超過20萬,真正重要的詞卻經常搞漏,如中考高考到 GRE的一萬五千核心詞匯,他們居然能缺少兩千左右。對比英國國傢語料庫(BNC)的詞頻數據,前十萬高頻詞匯缺少一萬二多;同時對比美國當代語料庫前六萬高頻詞匯,任然缺少一萬多。
國內詞庫制作之不嚴謹,可見一斑,朗道字典(GoldenDict / StarDict配套的那個),居然連 “learn” 這個單詞都沒收,搞笑吧?我不知道是 bug還是什麼。號稱收詞量最大的簡明英漢詞典,居然沒有 “longtime”,當然他有詞組“long time”,但是近年來 longtime已經鏈接為一個詞瞭,並且詞頻很高。詞頻上升比較快的還有 Taliban ,這些他們都沒收收錄。喜聞樂見的《21世紀》,也有不少漏詞,比如神奇的 through 和 dalit ,包括不限於國內某些著名的商業詞典,很多號稱收詞量多,但是他們把詞給收偏瞭,這就是人工選詞和校對不可避免的問題,所以我們需要更科學的根據各類考試大綱和語料庫對選詞進行自動矯正。
到底該收錄哪些單詞呢?就基礎詞匯而言,選詞程序先後分析瞭:
語料數據:考試大綱(四六級,托福雅思GRE等,必須覆蓋到位),BNC語料庫,美國當代語料庫,華爾街日報(進20年語料數據庫),經濟學人12萬詞頻表。
詞典索引:http://Vocabulary.com,《牛津大辭典》,http://wiktionary.org,《朗文6》,《科林斯12》,《21世紀》,《臺灣國傢教育研究院雙語詞匯》,cdict-1.0-1.rpm(Linux 下開源英漢詞典)。
演示3:動詞短語
閱讀時就怕出現這種每個詞都認識,但是連在一起都不認識的詞組短語:
kisses off
get away with
kiss and tell
round off
a sticky patch
double down on