image.png
隨著越來越多的企業采用機器學習來支持其決策過程,充分瞭解 ML 模型如何進行預測至關重要。構建和擴展模型生產已不足以改善結果。這些模型需要透明才能理解它們為什麼做出特定的預測。
數據科學傢、機器學習工程師和領域專傢缺乏深入研究他們的模型並檢查“為什麼”的能力。它們僅限於來自標準摘要指標(如性能圖表和描述性統計數據)的基本見解。能夠解釋模型預測是實現進一步測試、實驗、改進性能和更明智決策的基礎。在具有相當高的計算能力和更復雜算法的時代,模型準確性不再是數據科學傢的禍根。新的挑戰是理解並能夠解釋為什麼模型會以這種方式運行,以及哪些特性是重要的。這就是模型可解釋性的用武之地。
在本文中,您將瞭解到:
- 什麼是可解釋性?
- 為什麼可解釋性很重要?
- 如何使用 Aporia 實現模型可解釋性
什麼是可解釋性?
機器學習中的可解釋性是基於數據特征、使用的算法和相關模型的環境,以人類可理解的方式理解模型輸出的能力。 基本上,它是分析和理解 ML 模型提供的結果的廣泛概念。 這是對“黑盒”模型概念的解決方案,它表示很難理解模型是如何得出具體決策的。
用於解決此概念的另一個短語是可解釋的 AI(XAI),它描述瞭一組方法和工具,使人類能夠理解和信任所創建的結果和輸出。
 image.png
image.png
重要的是要指出,可解釋性不僅適用於機器學習工程師或數據科學傢,它適用於所有人。 每個人都應該可以理解模型的任何解釋——無論他們是數據科學傢、企業主、客戶還是用戶。 因此,它應該既簡單又信息豐富。
那麼,為什麼可解釋性在機器學習中很重要?
為什麼您需要 ML 模型的可解釋性
- 信任:人們通常信任他們熟悉或已有知識的事物。因此,如果他們不瞭解模型的內部運作,他們就無法信任它,尤其是在醫療保健或金融等高風險領域。如果不瞭解它如何以及為什麼做出決定以及這些決定是否合理,就不可能信任機器學習模型。
- 法規和合規性:保護科技消費者的法規要求,在公眾使用技術之前,必須達到很強的可解釋性。例如,如果受到人工智能算法的影響,歐盟第 679 條規定賦予消費者“對經過此類評估做出的決定作出解釋並質疑該決定的權利”。此外,數據科學傢、審計師和業務決策者都必須確保他們的 AI 符合公司政策、行業標準和政府法規。
- ML 公平性和偏見:當涉及到糾正模型的公平性和偏見時,如果沒有模型的可解釋性,就真的無法檢測它來自數據中的什麼地方。由於機器學習模型中普遍存在偏見和漏洞,瞭解模型的工作原理是在將其部署到生產環境之前的首要任務。
- 調試:如果不瞭解“錯誤”特征或算法,就不可能獲得所需的輸出。因此,模型可解釋性對於在開發階段調試模型至關重要。
- 增強控制:當您瞭解模型的工作原理時,您會看到未知的漏洞和缺陷。然後,在低風險情況下快速識別和糾正錯誤的能力就變得容易瞭。
- 易於理解和提問的能力:瞭解模型的特征如何影響模型輸出有助於您進一步提問和改進模型。
在考慮瞭可解釋性為何如此重要的這些原因之後,瞭解可解釋性的范圍至關重要。
可解釋性方法
模型可解釋性有三種不同的方法:
- 全局可解釋性方法
- 局部可解釋性方法
- 分段可解釋性方法
全局可解釋性方法
全局方法從整體上解釋瞭模型的行為。全局可解釋性可幫助您瞭解模型中的哪些特征有助於模型的整體預測。在模型訓練期間,全局可解釋性向利益相關者提供有關模型在做出決策時使用的特征的信息。例如,查看推薦模型的產品團隊可能想知道哪些特征(關系)最能激發或吸引客戶。
局部(Local)可解釋性方法
局部解釋有助於理解模型在局部鄰域中的行為,即它解釋瞭數據中的每個特征以及每個特征如何單獨對模型的預測做出貢獻。
局部可解釋性有助於找到生產中特定問題的根本原因。它還可用於幫助您發現哪些特征對做出模型決策最有影響。這很重要,尤其是在金融和健康等行業,其中單個特征幾乎與所有特征的組合一樣重要。例如,假設您的信用風險模型拒絕瞭貸款申請人。借助局部可解釋性,您可以瞭解做出此決定的原因以及如何更好地為申請人提供建議。它還有助於瞭解模型對部署的適用性。
分段(群組)可解釋性方法 [Segment(Cohort)]
介於全局和局部可解釋性之間的是分段。這解釋瞭數據的片段或切片如何有助於模型的預測。在模型驗證期間,分段可解釋性有助於解釋模型在模型表現良好的群組與模型表現不佳的群組之間的預測差異。當異常值出現在本地鄰域或數據切片中時,它還有助於解釋異常值。
註意:Local 和 Cohort (Segment) 的可解釋性都可以用來解釋異常值。
目前有多種可解釋性的方法,例如:Shap、部分依賴圖、LIME、ELI5。
在處理可解釋性時想到的一個問題是:模型的哪些部分正在被解釋,為什麼這部分很重要?讓我們看看這個問題……
正在解釋模型的哪些部分以及為什麼特定部分很重要?
- 特征:模型的特征通常是模型解釋的主要來源,因為它們構成瞭模型的主要組成部分。
- 數據特性:這些可能包括:數據格式、數據完整性等。生產模型不斷變化。因此,記錄和監控這些變化以更好地理解和解釋模型的輸出非常重要。數據分佈變化會影響模型預測,因此維護數據分佈並充分瞭解數據特征對於模型可解釋性很重要。
- 算法:訓練模型時使用的算法和技術的選擇與數據本身一樣重要。這些算法定義瞭特征如何交互和組合以實現模型輸出。對訓練算法和技術的清晰理解對於實現模型的可解釋性至關重要。
為瞭實現可解釋性,您需要能夠在全局和局部解釋您的模型的工具。
如何使用 Aporia 實現可解釋性
Aporia 的全棧 ML 可觀察性解決方案為數據科學傢和 ML 工程師提供瞭可見性、監控和自動化、調查工具和可解釋性,以瞭解模型為何預測它們的行為、它們在生產中的表現如何以及可以改進的地方。
使用 Aporia 的可解釋人工智能工具
要瞭解可解釋性功能在 Aporia 中的工作原理,請使用您的電子郵件登錄 Aporia。轉到演示模型,然後從那裡轉到數據點儀表板。 接下來單擊解釋按鈕。
 image.png
image.png
對於此模型,您可以看到特征如何對模型的預測做出貢獻。
您還可以獲得與主要利益相關者分享的業務說明。
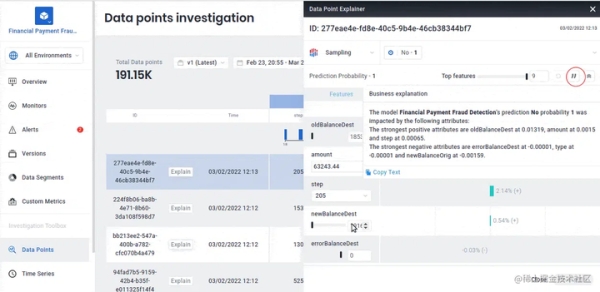 image.png
image.png
您還可以通過單擊“重新解釋”來更改任何特征值,並查看它如何影響預測。這使您可以調試模型以進行特定預測。
image.png
Aporia 的可解釋性功能可讓您深入瞭解模型並更好地理解模型:
- 數據集中所有特征的預測,即全局可解釋性
- 每個特征對模型預測的單獨貢獻,即局部可解釋性
- 分段可解釋性
隨著機器學習模型繼續被所有行業采用,並迅速成為組織決策過程的標準關鍵組成部分,ML 模型是“黑匣子”的想法將被揭穿。 模型預測可以用 Aporia 等可解釋的 AI 工具來解釋。
Aporia 使 ML 模型可解釋,幫助數據科學和 ML 團隊更好地理解他們的模型,並以更有效和負責任的方式利用他們的機器學習。
原文鏈接:A Hands-On Guide to Explainability